

Iris flower classification using KNN
The Iris flower data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper The use of multiple measurements in taxonomic problems. It is sometimes called Anderson's Iris data set because Edgar Anderson collected the data to quantify the morphologic variation of Iris flowers of three related species. The data set consists of 50 samples from each of three species of Iris (Iris Setosa, Iris virginica, and Iris versicolor). Four features were measured from each sample: the length and the width of the sepals and petals, in centimeters.
Collect the dataset from https://www.kaggle.com/datasets/arshid/iris-flower-dataset
#import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#create the dataframe
df=pd.read_csv("E:\dataset\IRIS.csv")
df.head()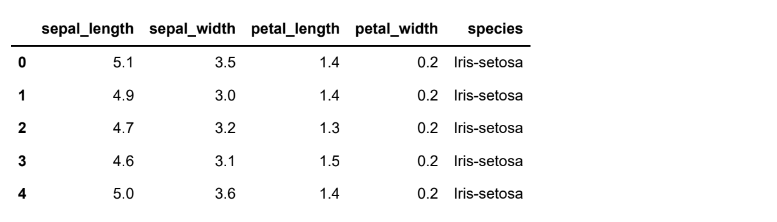
df.shapeOutput : (150, 5)
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KBdf.describe().T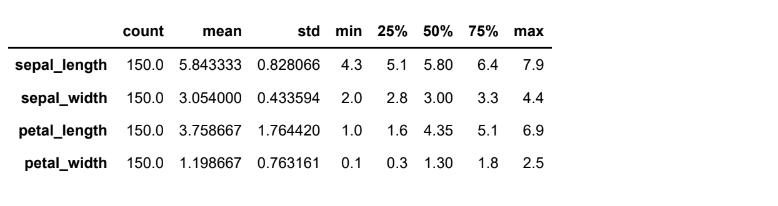
#check mssing values
df.isnull().sum()Output:
sepal_length 0
sepal_width 0
petal_length 0
petal_width 0
species 0
dtype: int64
#Choose X and y
X=df.iloc[:,:-1].values
y=df.iloc[:,4].valuesfrom sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,rando#Scaling operation
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()scaler.fit(X_train)Output : StandardScaler()
X_train=scaler.transform(X_train)
X_test=scaler.transform(X_test)y_testOutput:
array(['Iris-virginica', 'Iris-versicolor', 'Iris-setosa',
'Iris-virginica', 'Iris-setosa', 'Iris-virginica', 'Iris-setosa',
'Iris-versicolor', 'Iris-versicolor', 'Iris-versicolor',
'Iris-virginica', 'Iris-versicolor', 'Iris-versicolor',
'Iris-versicolor', 'Iris-versicolor', 'Iris-setosa',
'Iris-versicolor', 'Iris-versicolor', 'Iris-setosa', 'Iris-setosa',
'Iris-virginica', 'Iris-versicolor', 'Iris-setosa', 'Iris-setosa',
'Iris-virginica', 'Iris-setosa', 'Iris-setosa', 'Iris-versicolor',
'Iris-versicolor', 'Iris-setosa', 'Iris-virginica',
'Iris-versicolor', 'Iris-setosa', 'Iris-virginica',
'Iris-virginica', 'Iris-versicolor', 'Iris-setosa',
'Iris-versicolor'], dtype=object)
#create KNN model
from sklearn.neighbors import KNeighborsClassifier
model=KNeighborsClassifier()#trained the model
model.fit(X_train,y_train)Output: KNeighborsClassifier()
#predict
y_pred=model.predict(X_test)
print(y_pred)['Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-virginica'
'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor'
'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor'
'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa'
'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa'
'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa'
'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor'
'Iris-versicolor' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor'
'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'
'Iris-setosa' 'Iris-virginica']
from sklearn.metrics import confusion_matrix, classification_report
print(classification_report(y_test,y_pred))
print(confusion_matrix(y_test,y_pred))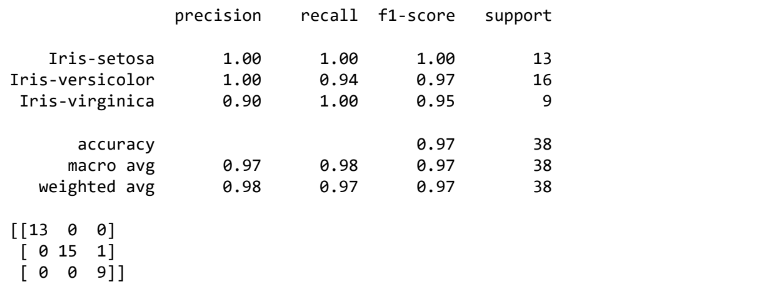
from sklearn import metrics
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9736842105263158
About the Author

Silan Software is one of the India's leading provider of offline & online training for Java, Python, AI (Machine Learning, Deep Learning), Data Science, Software Development & many more emerging Technologies.
We provide Academic Training || Industrial Training || Corporate Training || Internship || Java || Python || AI using Python || Data Science etc



PreviousNext
Join our newsletter for the latest updates.
About us
Our Services
Contact Us
Our Courses
Learn Python | Learn AI | Learn Machine Learning | Learn Deep Learning | Learn Core Java | Learn Java JSP | Learn Java Servlet | Learn Java Spring Core | Learn Spring Boot | Learn Power BI | Learn DAA | Learn HTML | Learn SQL | Learn C Programming | Learn Bootstrap | Learn Git | Learn JavaScript | Learn Data Structure Using C | Learn RDBMS | Learn Data Science | Learn PHP
Our Tutorials
Python Tutorial | AI Tutorial | Machine Learning Tutorial | Deep Learning Tutorial | Core Java Tutorial | Java JSP Tutorial | Java Servlet Tutorial | Java Spring Tutorial | Spring Boot Tutorial | Power BI Tutorial | DAA Tutorial | HTML Tutorial | SQL Tutorial | C Programming Tutorial | Bootstrap Tutorial | Git Tutorial | JavaScript Tutorial | Data Structure Using C Tutorial | RDBMS Tutorial | Data Science Tutorial | PHP Tutorial
Copyright © 2023 Pythontpoint Powered by Silan Software Pvt. Ltd. All rights reserved.