

Overfitting in Machine Learning
In the real world, the dataset present will never be clean and perfect. It means each dataset contains impurities, noisy data, outliers, missing data, or imbalanced data. Due to these impurities, different problems occur that affect the accuracy and the performance of the model. One of such problems is Overfitting in Machine Learning. Overfitting is a problem that a model can exhibit.
A statistical model is said to be overfitted if it can’t generalize well with unseen data.
Before understanding overfitting, we need to know some basic terms, which are:
Noise: Noise is meaningless or irrelevant data present in the dataset. It affects the performance of the model if it is not removed.
Bias: Bias is a prediction error that is introduced in the model due to oversimplifying the machine learning algorithms. Or it is the difference between the predicted values and the actual values.
Variance: If the machine learning model performs well with the training dataset, but does not perform well with the test dataset, then variance occurs.
Generalization: It shows how well a model is trained to predict unseen data.
What is Overfitting?
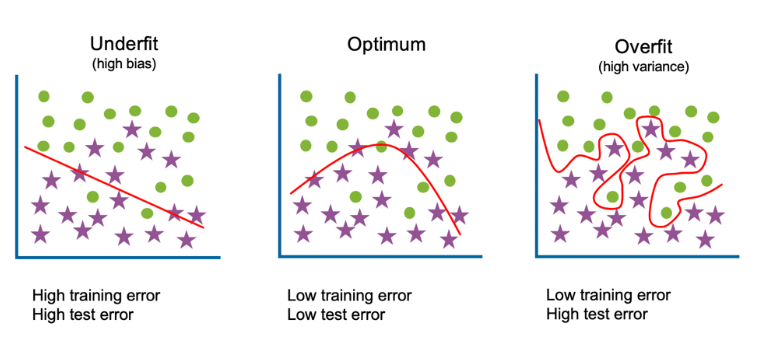
Example to Understand Overfitting
We can understand overfitting with a general example. Suppose there are three students, X, Y, and Z, and all three are preparing for an exam. X has studied only three sections of the book and left all other sections. Y has a good memory, hence memorized the whole book. And the third student, Z, has studied and practiced all the questions. So, in the exam, X will only be able to solve the questions if the exam has questions related to section 3. Student Y will only be able to solve questions if they appear exactly the same as given in the book. Student Z will be able to solve all the exam questions in a proper way.
The same happens with machine learning; if the algorithm learns from a small part of the data, it is unable to capture the required data points and hence under fitted.
Suppose the model learns the training dataset, like the Y student. They perform very well on the seen dataset but perform badly on unseen data or unknown instances. In such cases, the model is said to be Overfitting.
And if the model performs well with the training dataset and also with the test/unseen dataset, similar to student Z, it is said to be a good fit.
How to detect Overfitting?
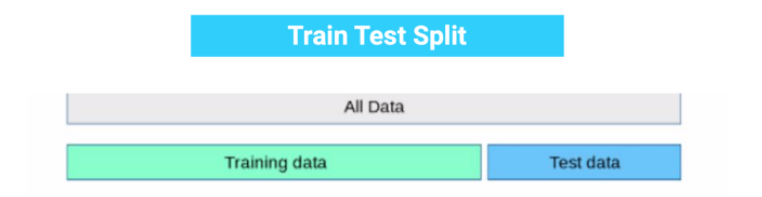
Overfitting in the model can only be detected once you test the data. To detect the issue, we can perform Train/test split.
In the train-test split of the dataset, we can divide our dataset into random test and training datasets. We train the model with a training dataset which is about 80% of the total dataset. After training the model, we test it with the test dataset, which is 20% of the total dataset.
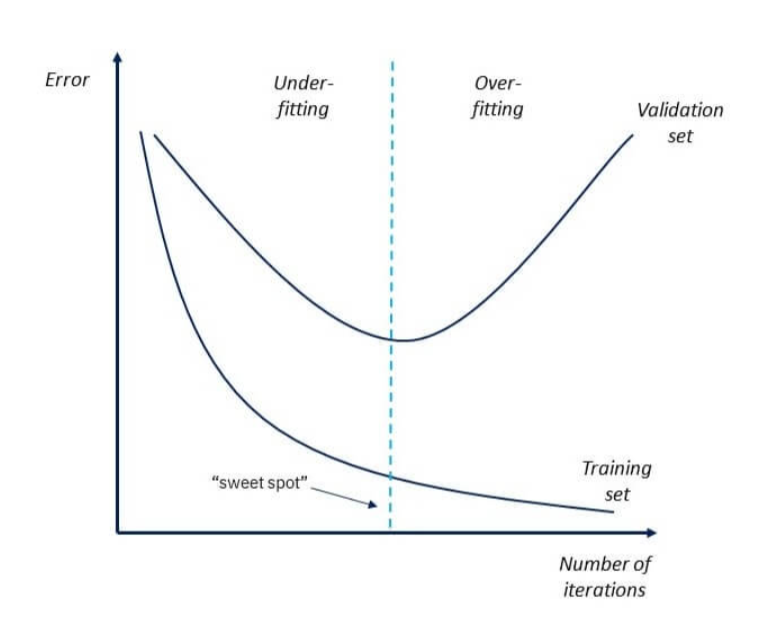
Now, if the model performs well with the training dataset but not with the test dataset, then it is likely to have an overfitting issue.
For example, if the model shows 85% accuracy with training data and 50% accuracy with the test dataset, it means the model is not performing well.
About the Author

Silan Software is one of the India's leading provider of offline & online training for Java, Python, AI (Machine Learning, Deep Learning), Data Science, Software Development & many more emerging Technologies.
We provide Academic Training || Industrial Training || Corporate Training || Internship || Java || Python || AI using Python || Data Science etc



PreviousNext
Join our newsletter for the latest updates.
About us
Our Services
Contact Us
Our Courses
Learn Python | Learn AI | Learn Machine Learning | Learn Deep Learning | Learn Core Java | Learn Java JSP | Learn Java Servlet | Learn Java Spring Core | Learn Spring Boot | Learn Power BI | Learn DAA | Learn HTML | Learn SQL | Learn C Programming | Learn Bootstrap | Learn Git | Learn JavaScript | Learn Data Structure Using C | Learn RDBMS | Learn Data Science | Learn PHP
Our Tutorials
Python Tutorial | AI Tutorial | Machine Learning Tutorial | Deep Learning Tutorial | Core Java Tutorial | Java JSP Tutorial | Java Servlet Tutorial | Java Spring Tutorial | Spring Boot Tutorial | Power BI Tutorial | DAA Tutorial | HTML Tutorial | SQL Tutorial | C Programming Tutorial | Bootstrap Tutorial | Git Tutorial | JavaScript Tutorial | Data Structure Using C Tutorial | RDBMS Tutorial | Data Science Tutorial | PHP Tutorial
Copyright © 2023 Pythontpoint Powered by Silan Software Pvt. Ltd. All rights reserved.