

Types of Clustering Methods
The clustering methods are broadly divided into Hard clustering (datapoint belongs to only one group) and Soft Clustering (data points can belong to another group also). But there are also other various approaches of Clustering exist. Below are the main clustering methods used in Machine learning:
Partitioning Clustering
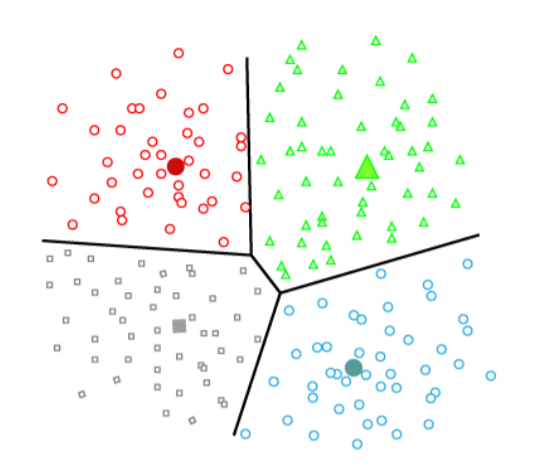
It is a type of clustering that divides the data into non-hierarchical groups. It is also known as the centroid-based method. The most common example of partitioning clustering is the K-Means Clustering algorithm.
In this type, the dataset is divided into a set of k groups, where K is used to define the number of pre-defined groups. The cluster center is created in such a way that the distance between the data points of one cluster is minimum as compared to another cluster centroid.
Density-Based Clustering
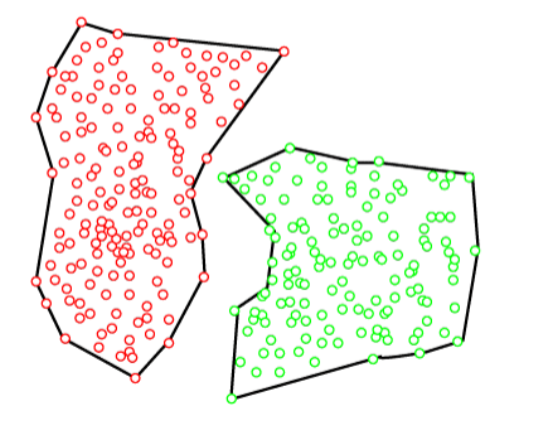
The density-based clustering method connects the highly-dense areas into clusters, and the arbitrarily shaped distributions are formed as long as the dense region can be connected. This algorithm does it by identifying different clusters in the dataset and connects the areas of high densities into clusters. The dense areas in data space are divided from each other by sparser areas.
These algorithms can face difficulty in clustering the data points if the dataset has varying densities and high dimensions.
Distribution Model-Based Clustering
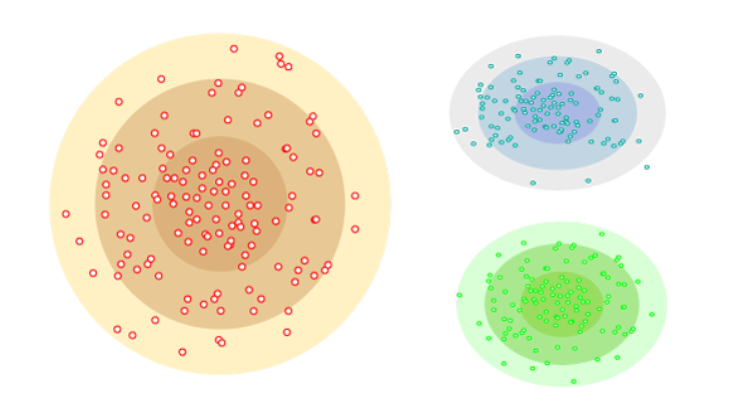
In the distribution model-based clustering method, the data is divided based on the probability of how a dataset belongs to a particular distribution. The grouping is done by assuming some distributions commonly Gaussian Distribution.
The example of this type is the Expectation-Maximization Clustering algorithm that uses Gaussian Mixture Models (GMM).
Hierarchical Clustering
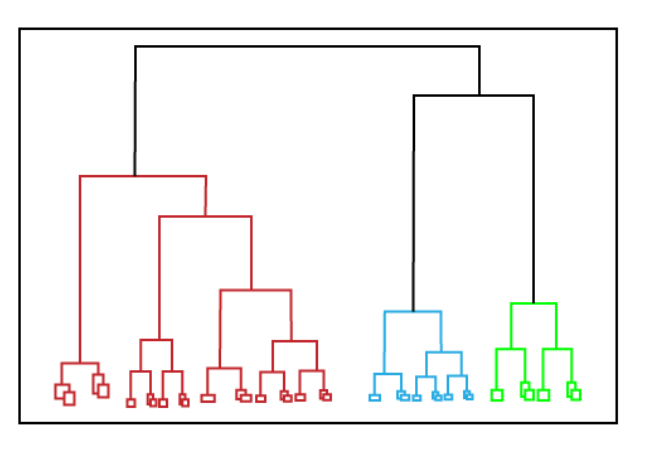
Hierarchical clustering can be used as an alternative for the partitioned clustering as there is no requirement of pre-specifying the number of clusters to be created. In this technique, the dataset is divided into clusters to create a tree-like structure, which is also called a dendrogram. The observations or any number of clusters can be selected by cutting the tree at the correct level. The most common example of this method is the Agglomerative Hierarchical algorithm.
Fuzzy Clustering
Fuzzy clustering is a type of soft method in which a data object may belong to more than one group or cluster. Each dataset has a set of membership coefficients, which depend on the degree of membership to be in a cluster. Fuzzy C-means algorithm is the example of this type of clustering; it is sometimes also known as the Fuzzy k-means algorithm.
About the Author

Silan Software is one of the India's leading provider of offline & online training for Java, Python, AI (Machine Learning, Deep Learning), Data Science, Software Development & many more emerging Technologies.
We provide Academic Training || Industrial Training || Corporate Training || Internship || Java || Python || AI using Python || Data Science etc



PreviousNext
Join our newsletter for the latest updates.
About us
Our Services
Contact Us
Our Courses
Learn Python | Learn AI | Learn Machine Learning | Learn Deep Learning | Learn Core Java | Learn Java JSP | Learn Java Servlet | Learn Java Spring Core | Learn Spring Boot | Learn Power BI | Learn DAA | Learn HTML | Learn SQL | Learn C Programming | Learn Bootstrap | Learn Git | Learn JavaScript | Learn Data Structure Using C | Learn RDBMS | Learn Data Science | Learn PHP
Our Tutorials
Python Tutorial | AI Tutorial | Machine Learning Tutorial | Deep Learning Tutorial | Core Java Tutorial | Java JSP Tutorial | Java Servlet Tutorial | Java Spring Tutorial | Spring Boot Tutorial | Power BI Tutorial | DAA Tutorial | HTML Tutorial | SQL Tutorial | C Programming Tutorial | Bootstrap Tutorial | Git Tutorial | JavaScript Tutorial | Data Structure Using C Tutorial | RDBMS Tutorial | Data Science Tutorial | PHP Tutorial
Copyright © 2023 Pythontpoint Powered by Silan Software Pvt. Ltd. All rights reserved.